قفزة جديدة للذكاء الاصطناعي.. فيديوهات من صورة واحدة







كشفت شركتا Google وStability AI عن نماذج ذكاء اصطناعي جديدة بإمكانها إنتاج مقاطع فيديو باستخدام صورة واحدة فقط.
ويتنيز نموذج Google بتقديم فيديوهات تبدو واقعية للغاية، إذ يظهر في الفيديو شخص يتحدث بتعابير وجه واقعية ومقربة من الحقيقة. بالمقابل، قدمت الشركة الناشئة Stability AI فيديوهات ثلاثية الأبعاد تظهر فيديوهات من منظور بانورامي، مما يعطي تجربة تفاعلية ومشاهد متعددة الأبعاد.
ويشهد سوق نماذج الذكاء الاصطناعي، التي تركز على إنتاج الفيديوهات، تقدماً واسعاً في الفترة الأخيرة، وهذا بسبب الإبهار الذي أحدثه إعلان شركة OpenAI عن نموذجها الثوري Sora، الذي من المتوقع أن يصبح متاحاً بنهاية العام الحالي.
فيديوهات 3D
وكشفت Stability AI عن إطلاق نموذج جديد يحمل اسم "Stable Video 3D"، أو اختصاراً SV3D، والذي يمثل تطوراً في مجال إنشاء الفيديوهات ثلاثية الأبعاد.
ويتميز النموذج الجديد بالقدرة على إنتاج مقاطع فيديو ثلاثية الأبعاد باستخدام صورة واحدة فقط، ويعتمد على تقنية "Stable Video Diffusion" وزوايا عرض محددة للعناصر لتحقيق هذا الأمر.
ويتميز SV3D باهتلافه عن النماذج الحالية المتاحة في السوق، مثل نماذج Zero123 وZero123XL، إذ يقدم مستوى جديداً من التحكم في إنشاء مجسمات ثلاثية الأبعاد لعناصر مأخوذة من صور ثنائية الأبعاد. وبفضل هذه التقنية الجديدة، يمكن عرض العناصر المنشأة من أي زاوية تخيلية، مما يضيف مرونة وتفاعلية أكبر لتجربة المستخدم.
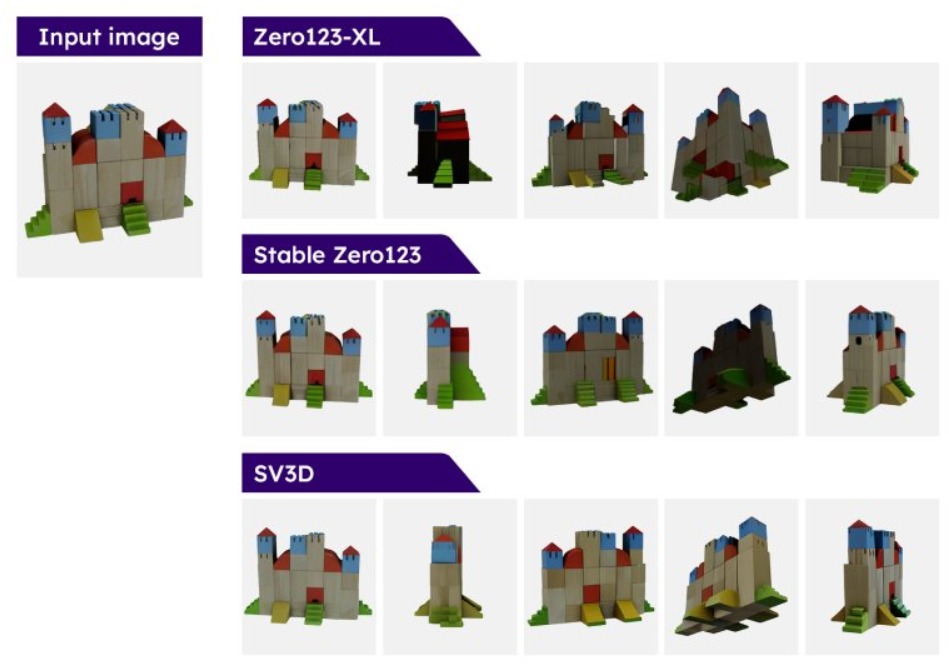
وترجع دقة إنشاء المجسمات ثلاثية الأبعاد من صورة واحدة إلى قدرة النموذج الجديد على تحسين مجال الإشعاع العصبي ثلاثي الأبعاد NeRF، إلى جانب رفع جودة إدراك النموذج لعلاقة المجسم 3D للعنصر مع الضوء، مما يعطي تصميماً أكثر واقعية خلال تحريكه بشكل دائري.
وأشارت الشركة إلى أن نموذجها الجديد متاح للاستخدام التجاري في عرض المنتجات المختلفة، لعملائها المشتركين في خدمتها Stability AI Membership.
"أفاتارات" بشرية
أما نموذج Google المسمى VLOGGER، فيعتمد على استخدام أنظمة تعلم الآلة، لإنشاء مقطع فيديو لشخص من صورة واحدة له، وجعله يتحدث بكلام محدد بأي لغة.
وأشار باحثو Google إلى أن النموذج الجديد يعتمد على نهج مختلف في إنشاء هذا النوع من الفيديوهات، فبدلاً من تحليل الوجوه وملامحها كل منها على حدة ومن ثم يتم إعادة تجميع تلك البيانات لإنشاء مقطع فيديو يظهر حركة الوجه، فإن نموذج VLOGGER يدرك الصورة الكاملة للوجه مجملاً.
والسر في القدرة الكبيرة لنموذج Google الجديد يكمن في قاعدة بيانات عملاقة، تحمل اسم MENTOR، وتحتوي على 800 ألف صورة للوجوه، و2000 ساعة من فيديوهات الوجوه لأشخاص يتحدثون وينفعلون.
وترى Google النموذج الجديد بأنه خطوة نحو مستقبل يعتمد بشكل أكبر على روبوتات دردشة رقمية متجسدة، أي يكون لها وجه ديجيتال يظهر انفعالاتها بشكل واقعي، ويمكنها التفاعل بشكل أكثر بشرية مع المستخدمين عبر إجراء تواصل بالنظر Eye Contact، والحديث المباشر، وكذلك إيماءات الوجه واليد.
الشرق





